Abstract
While language models have become impactful in many real-world applications, video generation remains largely confined to entertainment. Motivated by video's inherent capacity to demonstrate physical-world information that is difficult to convey through language alone (e.g., imagine teaching someone to tie a tie using only text), we identify an underutilized opportunity to extend video as a new answer modality for Next-Event Prediction (NEP), formalized as Video-Next-Event Prediction (VNEP). While the established NEP task takes a video with a procedural or predictive question as input to predict the next event in text, VNEP requires dynamic video responses. This shift from telling to showing unlocks more intuitive and customized answers for procedural learning and creative exploration. However, this task remains challenging for existing models, as it demands an understanding of multimodal input, instruction-conditioned reasoning, and the generation of video with visual and semantic consistency. To address this, we introduce VANS, a model that leverages reinforcement learning to align a Vision-Language Model (VLM) with a Video Diffusion Model (VDM) for VNEP. The core of VANS is our proposed Joint-GRPO that orchestrates the VLM and VDM to function as a unit. Driven by a shared reward on their respective output, it optimizes the VLM to produce captions that are both accurate and friendly to visualize, while guiding the VDM to generate videos that are faithful to these captions and the input visual context. To enable this learning, we craft VANS-Data-100K, a dedicated dataset for the VNEP task. Experiments on procedural and predictive benchmarks demonstrate that VANS achieves state-of-the-art performance in both video event prediction and visualization.
VANS-Data-100K Dataset
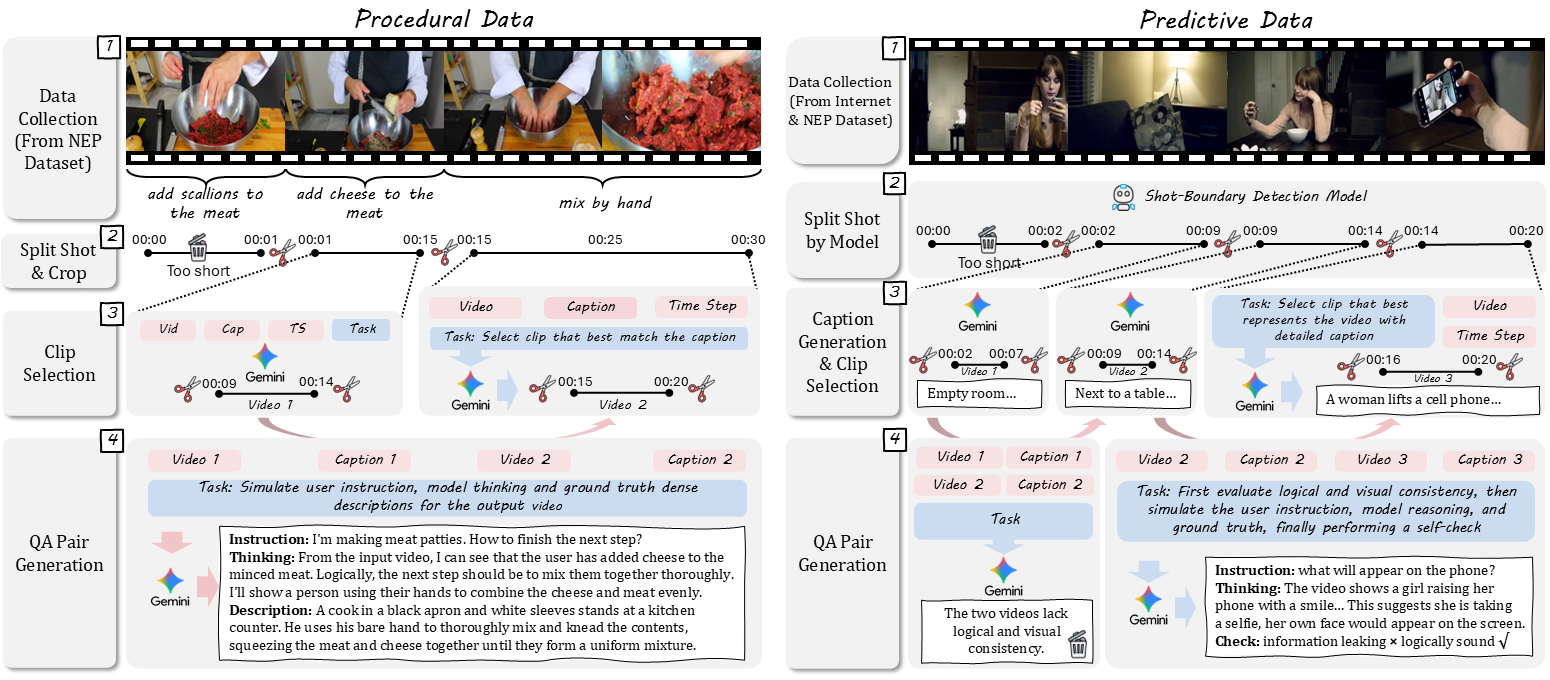
We construct VANS-Data-100K, a comprehensive dataset specifically designed for Video-Next-Event Prediction (VNEP), comprising 30K procedural and 70K predictive samples. Each sample contains an input video, instructional question, and multi-modal answer (text and video), addressing the limitations of existing NEP datasets in video quality and question diversity.
VANS Model
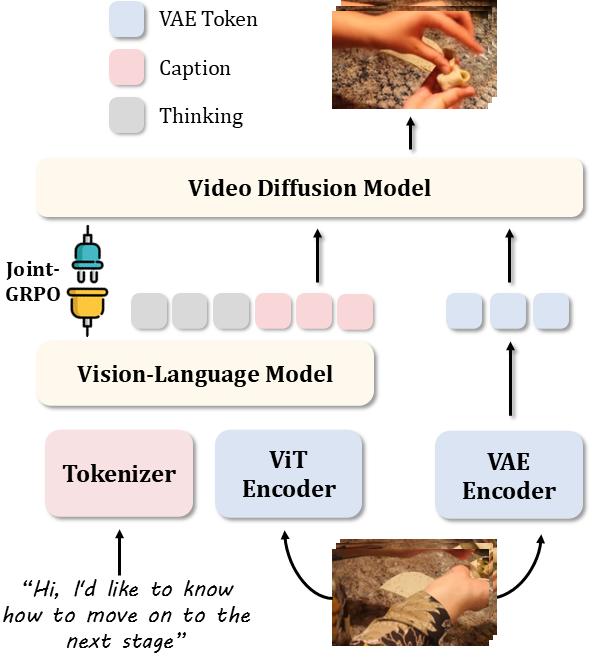
Overall architecture of VANS: Dual-path processing with VLM for reasoning and VDM for video generation, conditioned on both semantic captions and visual context.
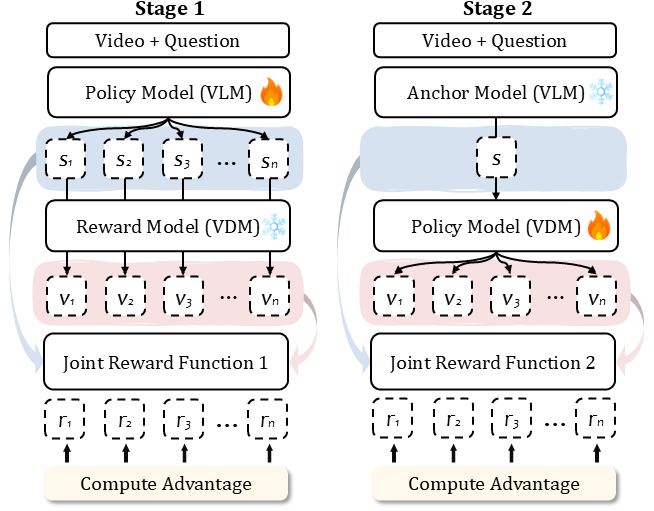
Joint-GRPO: Two-stage co-steering optimization that bridges the semantic-to-visual gap between VLM and VDM.
Architecture Design & Challenge
Our proposed VANS processes input videos and questions through a dual-path architecture: the VLM performs instruction-grounded reasoning to generate textual captions describing predicted next events, while the VDM synthesizes videos conditioned on both these semantic guides and low-level visual cues from input frames.
However, this design faces a fundamental limitation: the VLM and VDM are optimized in isolation. The VLM is trained for textual accuracy but receives no feedback on whether its descriptions lead to visually plausible videos. Conversely, the VDM faces the challenge of coordinating two conditioning signals: the VLM's specific caption and the input's visual context. While SFT equips the VDM with basic capabilities, achieving consistent performance on both semantic accuracy and visual fidelity requires further refinement.
This disconnect creates a semantic-to-visual gap where both models operate without awareness of each other's constraints and capabilities. To resolve this, we introduce Joint-GRPO to orchestrate the two models into a cohesive unit for VNEP.
Joint-GRPO: Bridging the Semantic-Visual Gap
Joint-GRPO coordinates the VLM and VDM using a joint reward function through structured two-stage optimization, enabling effective co-steering while avoiding the attribution problems of one-stage joint training.
Stage 1: Visualization-Friendly VLM Tuning
Optimizes the VLM policy while keeping VDM frozen. The joint reward combines format adherence, text fidelity (ROUGE-L), and video fidelity (CLIP Similarity), guiding the VLM to generate captions that are not only semantically accurate but also visually plausible and actionable for the VDM.
Stage 2: Context-Faithful VDM Adaptation
Optimizes the VDM policy using the improved VLM as a frozen anchor. The reward function ensures visual coherence with input context while enforcing strict semantic alignment with the VLM's caption through CLIPScore, preventing the VDM from ignoring captions and merely reconstructing input videos.
Through this two-stage optimization, the VLM and VDM co-evolve into a synergistic unit, effectively bridging the semantic-to-visual gap and enabling high-quality Video-Next-Event Prediction.
Qualitative Comparison on Procedural Questions
Click on a question to view the input video and corresponding answers
Qualitative Comparison on Predictive Questions
Click on a question to view the input video and corresponding answers
Generalization on Multi-Future Prediction
Same input video with different questions leads to different future prediction
Generalization on Reasoning Image-to-Video Generation
Comparison on UI2V-Bench benchmark for reasoning image-to-video generation
Citation
@article{cheng2025video,
title={Video-as-Answer: Predict and Generate Next Video Event with Joint-GRPO},
author={Cheng, Junhao and Hou, Liang and Tao, Xin and Liao, Jing},
journal={arXiv preprint arXiv:2511.16669},
year={2025}
}Acknowledgement
This work was supported by Kuaishou Technology.
We are grateful to Yicheng Xiao for his assistance with this project. We also acknowledge AnimeShooter and DiffSynth-Studio for their foundational codebase and informative homepages, which were instrumental to our work.